#185 History of Data-centrical Applications (revisited)
Check out my new book AI Augmented Teams on Amazon or on my website paidar.ai/books.
The first episode of this podcast was released 185 episodes ago. In this episode, the host Darren Pulsipher redoes episode one to provide updated information on the history of data-centric application development. He discusses how new technologies like edge computing and AI have impacted data generation and the need for better data management.
Early Data Processing
In the early days of computing, applications were built to transform data from one form into another valuable output. Early computers like the ENIAC and Turing's machine for breaking the Enigma code worked by taking in data, processing it via an application, and outputting it to storage. Over time, technology advanced from specialized hardware to more generalized systems with CPUs and networking capabilities. This allowed data sharing between systems, enabling new applications.
Emergence of Virtualization
In the 1990s and 2000s, virtualization technology allowed entire systems to be encapsulated into virtual machines. This decoupled the application from the hardware, increasing portability. With the rise of Linux, virtual machines could now run on commodity x86 processors, lowering costs and barriers to entry. Virtualization increased ease of use but introduced new security and performance concerns.
The Rise of Cloud Computing
Cloud computing is built on virtualization, providing easy, on-demand access to computing resources over the internet. This allowed organizations to reduce capital expenditures and operational costs. However, moving to the cloud meant security, performance, and integration challenges. Cloud's pay-as-you-go model enabled new use cases and made consuming technology resources easier overall.
Containerization and New Complexity
Containerization further abstracted applications from infrastructure by packaging apps with their runtimes, configuration, and dependencies—this increased portability and complexity in managing distributed applications and data across environments. Locality of data became a key concern, contradicting assumptions that data is available anywhere. This evolution resulted in significant new security implications.
Refocusing on Data
To address these challenges, new architectures like data meshes and distributed information management focus on data locality, governance, lifecycle management, and orchestration. Data must be contextualized across applications, infrastructure, and users to deliver business value securely. Technologies like AI are driving data growth exponentially across edge environments. More robust data management capabilities are critical to overcoming complexity and risk.
Security Concerns with Data Distribution
The distribution of data and applications across edge environments has massively increased the attack surface. Principles of zero trust are being applied to improve security, with a focus on identity and access controls as well as detection, encryption, and hardware roots of faith.
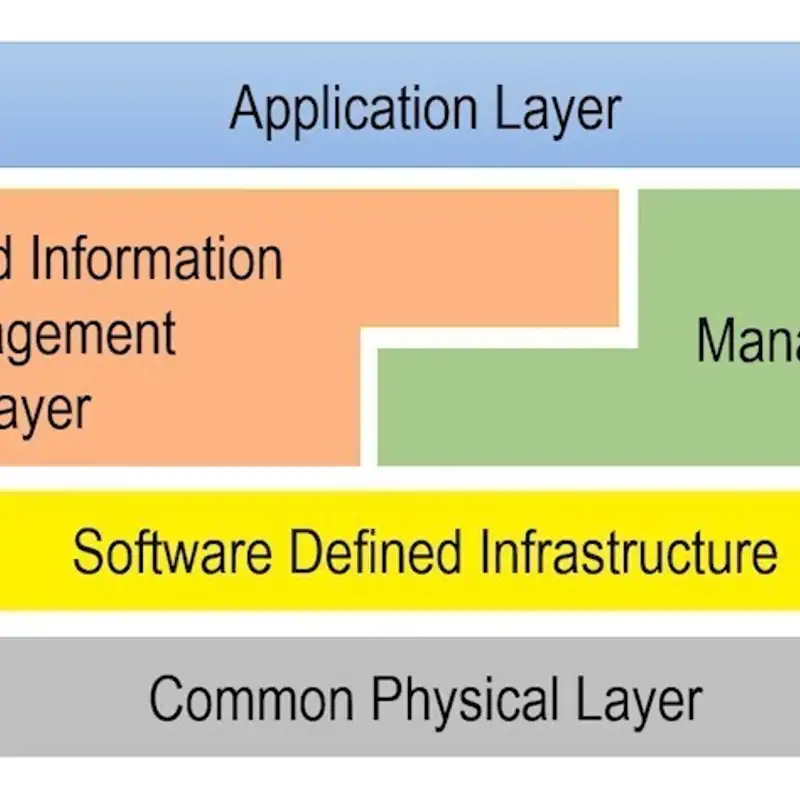
The Edgemere Architecture
The Edgemere architecture provides a model for implementing security across modern complex technology stacks spanning hardware, virtualization, cloud, data, and apps. Applying zero trust principles holistically across these layers is critical for managing risk. Robust cybersecurity capabilities like encryption and access controls are essential for delivering business value from data in the new era of highly distributed and interconnected systems.